Как работают поисковые системы. Поисковые системы Поисковые системы могут работать с
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
«Реферат написать»:

«Купить»:
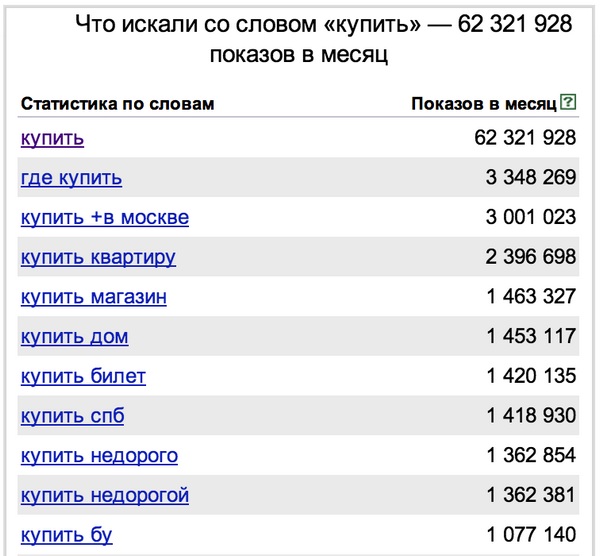
Но больше всего интересуются…

Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.

Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.

Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.

Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.
Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.

МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:

Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.
Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».
Поисковые системы (ПС) уже приличное время являются обязательной частью интернета. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и , понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.

Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Анадыри»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. А приучить пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?

Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самый известный и большой каталог в мире имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.

Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

По данным на сентябрь 2015 года , доли поисковых систем в мире распределены следующим образом:
- Google - 69,24 %;
- Bing - 12,26 %;
- Yahoo! - 9,19 %;
- Baidu - 6,48 %;
- AOL - 1,11 %;
- Ask - 0,23 %;
- Excite - 0,00 %

По данным на декабрь 2016 года , доли поисковых систем в Рунете:
- Яндекс - 48,40%
- Google - 45,10%
- Search.Mail.ru - 5,70%
- Rambler - 0,40%
- Bing - 0,30%
- Yahoo - 0,10%

Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.Модуль индексирования.
Данный компонент состоит из трех программ-роботов:Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.

«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.

Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) - комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Что это
DuckDuckGo - это довольно известная поисковая система с открытым исходным кодом. Серверы находятся в США. Кроме собственного робота, поисковик использует результаты других источников: Yahoo, Bing, «Википедии».
Чем лучше
DuckDuckGo позиционирует себя как поиск, обеспечивающий максимальную приватность и конфиденциальность. Система не собирает никаких данных о пользователе, не хранит логи (нет истории поиска), использование файлов cookie максимально ограничено.
DuckDuckGo не собирает личную информацию пользователей и не делится ею. Это наша политика конфиденциальности.
Гэбриел Вайнберг (Gabriel Weinberg), основатель DuckDuckGo
Зачем это вам
Все крупные поисковые системы стараются персонализировать поисковую выдачу на основе данных о человеке перед монитором. Этот феномен получил название «пузырь фильтров»: пользователь видит только те результаты, которые согласуются с его предпочтениями или которые система сочтёт таковыми.
Формирует объективную картину, не зависящую от вашего прошлого поведения в Сети, и избавляет от тематической рекламы Google и «Яндекса», основанной на ваших запросах. При помощи DuckDuckGo легко искать информацию на иностранных языках, тогда как Google и «Яндекс» по умолчанию отдают предпочтение русскоязычным сайтам, даже если запрос введён на другом языке.

Что это
not Evil - система, осуществляющая поиск по анонимной сети Tor. Для использования нужно зайти в эту сеть, например запустив специализированный .
not Evil не единственный поисковик в своём роде. Есть LOOK (поиск по умолчанию в Tor-браузере, доступен из обычного интернета) или TORCH (один из самых старых поисковиков в Tor-сети) и другие. Мы остановились на not Evil из-за недвусмысленного намёка на Google (достаточно посмотреть на стартовую страницу).
Чем лучше
Ищет там, куда Google, «Яндексу» и другим поисковикам вход закрыт в принципе.
Зачем это вам
В сети Tor много ресурсов, которые невозможно встретить в законопослушном интернете. И их число будет расти по мере того, как ужесточается контроль властей над содержанием Сети. Tor - это своеобразная сеть внутри Сети со своими социалками, торрент-трекерами, СМИ, торговыми площадками, блогами, библиотеками и так далее.
3. YaCy

Что это
YaCy - децентрализованная поисковая система, работающая по принципу сетей P2P. Каждый компьютер, на котором установлен основной программный модуль, сканирует интернет самостоятельно, то есть является аналогом поискового робота. Полученные результаты собираются в общую базу, которую используют все участники YaCy.
Чем лучше
Здесь сложно говорить, лучше это или хуже, так как YaCy - это совершенно иной подход к организации поиска. Отсутствие единого сервера и компании-владельца делает результаты полностью независимыми от чьих-то предпочтений. Автономность каждого узла исключает цензуру. YaCy способен вести поиск в глубоком вебе и неиндексируемых сетях общего пользования.
Зачем это вам
Если вы сторонник открытого ПО и свободного интернета, не подверженного влиянию государственных органов и крупных корпораций, то YaCy - это ваш выбор. Также с его помощью можно организовать поиск внутри корпоративной или другой автономной сети. И пусть пока в быту YaCy не слишком полезен, он является достойной альтернативой Google с точки зрения процесса поиска.
4. Pipl

Что это
Pipl - система, предназначенная для поиска информации о конкретном человеке.
Чем лучше
Авторы Pipl утверждают, что их специализированные алгоритмы ищут эффективнее, чем «обычные» поисковики. В частности, приоритетными являются профили социальных сетей, комментарии, списки участников и различные базы данных, где публикуются сведения о людях, например базы судебных решений. Лидерство Pipl в этой области подтверждено оценками Lifehacker.com, TechCrunch и других изданий.
Зачем это вам
Если вам нужно найти информацию о человеке, проживающем в США, то Pipl будет намного эффективнее Google. Базы данных российских судов, видимо, недоступны для поисковика. Поэтому с гражданами России он справляется не так хорошо.

Что это
FindSounds - ещё один специализированный поисковик. Ищет в открытых источниках различные звуки: дом, природа, машины, люди и так далее. Сервис не поддерживает запросы на русском языке, но есть внушительный список русскоязычных тегов, по которым можно выполнять поиск.
Чем лучше
В выдаче только звуки и ничего лишнего. В настройках можно выставить желаемый формат и качество звучания. Все найденные звуки доступны для скачивания. Имеется поиск по образцу.
Зачем это вам
Если вам нужно быстро найти звук мушкетного выстрела, удары дятла-сосуна или крик Гомера Симпсона, то этот сервис для вас. И это мы выбрали только из доступных русскоязычных запросов. На английском языке спектр ещё шире.
Если серьёзно, специализированный сервис предполагает специализированную аудиторию. Но вдруг и вам пригодится?

Что это
Wolfram|Alpha - вычислительно-поисковая система. Вместо ссылок на статьи, содержащие ключевые слова, она выдаёт готовый ответ на запрос пользователя. Например, если ввести в форму поиска «сравнить население Нью-Йорка и Сан-Франциско» на английском, то Wolfram|Alpha сразу выведет на экран таблицы и графики со сравнением.
Чем лучше
Этот сервис лучше других подходит для поиска фактов и вычисления данных. Wolfram|Alpha накапливает и систематизирует доступные в Сети знания из различных областей, включая науку, культуру и развлечения. Если в этой базе находится готовый ответ на поисковый запрос, система показывает его, если нет - вычисляет и выводит результат. При этом пользователь видит только и ничего лишнего.
Зачем это вам
Если вы, например, студент, аналитик, журналист или научный сотрудник, то можете использовать Wolfram|Alpha для поиска и вычисления данных, связанных с вашей деятельностью. Сервис понимает не все запросы, но постоянно развивается и становится умнее.

Что это
Метапоисковик Dogpile выводит комбинированный список результатов из поисковых выдач Google, Yahoo и других популярных систем.
Чем лучше
Во-первых, Dogpile отображает меньше рекламы. Во-вторых, сервис использует особый алгоритм, чтобы находить и показывать лучшие результаты из разных поисковиков. Как утверждают разработчики Dogpile, их системы формирует самую полную выдачу во всём интернете.
Зачем это вам
Если вы не можете найти информацию в Google или другом стандартном поисковике, поищите её сразу в нескольких поисковиках с помощью Dogpile.

Что это
BoardReader - система для текстового поиска по форумам, сервисам вопросов и ответов и другим сообществам.
Чем лучше
Сервис позволяет сузить поле поиска до социальных площадок. Благодаря специальным фильтрам вы можете быстро находить посты и комментарии, которые соответствуют вашим критериям: языку, дате публикации и названию сайта.
Зачем это вам
BoardReader может пригодиться пиарщикам и другим специалистам в области медиа, которых интересует мнение массовой по тем или иным вопросам.
В заключение
Жизнь альтернативных поисковиков часто бывает скоротечной. О долгосрочных перспективах подобных проектов Лайфхакер спросил бывшего генерального директора украинского филиала компании «Яндекс» Сергея Петренко .

Сергей Петренко
Бывший генеральный директор «Яндекс.Украины».
Что касается судьбы альтернативных поисковиков, то она проста: быть очень нишевыми проектами с небольшой аудиторией, следовательно без ясных коммерческих перспектив или, наоборот, с полной ясностью их отсутствия.
Если посмотреть на примеры в статье, то видно, что такие поисковики либо специализируются в узкой, но востребованной нише, которая, возможно только пока, не выросла настолько, чтобы оказаться заметной на радарах Google или «Яндекса», либо тестируют оригинальную гипотезу в ранжировании, которая пока не применима в обычном поиске.
Например, если поиск по Tor вдруг окажется востребованным, то есть результаты оттуда понадобятся хотя бы проценту аудитории Google, то, конечно, обычные поисковики начнут решать проблему, как их найти и показать пользователю. Если поведение аудитории покажет, что заметной доле пользователей в заметном количестве запросов более релевантными кажутся результаты, данные без учёта факторов, зависящих от пользователя, то «Яндекс» или Google начнут давать такие результаты.
«Быть лучше» в контексте этой статьи не означает «быть лучше во всём». Да, во многих аспектах нашим героям далеко до и «Яндекса» (даже до Bing далековато). Но зато каждый из этих сервисов даёт пользователю нечто такое, чего не могут предложить гиганты поисковой индустрии. Наверняка вы тоже знаете подобные проекты. Поделитесь с нами - обсудим.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Интернет - просто охренеть какая огромная штука. И в нем есть все . Общение с друзьями? Вот, пожалуйста - Facebook. Фотоальбом - в Instagram. Купить дачу? У меня уже есть «Веселый фермер». А энциклопедией давно пользовались? Зачем, ведь есть , которые знают все. И сегодня мне бы хотелось отдать должное этим чудо-сервисам. А точнее рассказать вам о том, как работает Яндекс поиск .
Помните Гермиону из саги о Гарри Поттере? Как вы думаете: почему она была такой сверхэрудированной всезнайкой? Правильно, потому что постоянно ходила где-то читала про всякие зелья, изучала разные заклинания, допытывалась до учителей по всем непонятным моментам. В общем, делала все, чтобы расширить свою базу знаний. Точно так же работает Яндекс поисковик. Еще до того, как вы задали ему вопрос, он уже кое-что узнал про вашу тему и сохранил себе в копилочку.
Как формируется поисковая база Яндекса
Пауки всемирной паутины
Знает несколько триллионов урлов. И каждый день он изучает по паре миллиардов из них . Делают это специальные роботы -пауки , краулеры . Они заходят на страницу , анализируют содержимое , делают копию и отправляют на сервер . А затем уходят по ссылкам на другие страницы. Так происходит знакомство поисковика с сайтом. Далее следует этап индексикации.
Если
произвести
нехитрые
математические
расчеты
, то
можно
выявить
, что
пауки
Яндекса
обойдут
все
известные
страницы
приблизительно
за
2
года
. Но
это
будет
неверно
, так
как
количество
урлов
постоянно
увеличивается
=> работа
по
созданию
поисковой
базы
бесконечна.
Индексикация
Определение сайта - это процесс добавления всей важной информации о странице в базу поисковика . То есть определяется язык , формируются данные об отдельных словах и вытаскиваются все ссылки исходящие на другие страницы . Кроме того у Yandex есть специальный инструмент , который называется логи Яндекса . Он изучает, как пользователь ведет себя в выдаче: на что кликает, а на что не кликает . Опираясь на все полученные параметры и задается поисковый индекс сайта .
Логи Яндекса широко применяются не только при индексикации , но и при ранжировании.
Составление поисковой базы
Поисковые индексы , полученные в ходе предыдущего этапа, отправляются в поисковую базу . У Яндекс поиска она функционирует на программной платформе мапредьюс . Здесь данные превращаются файлы и «остаются жить».
Суммарный объем данных YT приблизительно 50 петабайт = 51 200ТБ.
У поисковой базы данных есть еженедельное обновление - апдейт. Это тот момент, когда поисковый робот Яндекса, накачав определенное количество файлов и рассчитав для них все необходимые характеристики, принимает решение, что можно добавить эту информацию в поиск.
Согласно статистическим данным Игоря Ашманова - специалиста по поисковым системам в интернете, полнота поисковой базы у Яндекса (красные на графике) в несколько раз выше , чем у их ближайшего конкурента Google (черные) .

Пока индекс - времязатратный и протекает комплексно сразу для большого количества данных . Поэтому у Яндекса есть специальный быстрый контур , который может добавлять и доносить до пользователя отдельные , срочные файлы . Ну , например , новости в реальном времени .
Как работает сам Яндекс поиск
Любой
запрос
в
поисковой
системе
Яндекс
проходит
по
следующей
схеме.
Балансеры
- это
машины, которые
агрегируют
выдачу.
Построение
выдачи
формируется
из
результатов
трех
средних
метапоисков
. Поясню
, что
это
значит
. В выдаче
вы
видите
результаты
запроса
по
страницам
, картинкам
и
видео
. Происходит
это
потому,
что
ваш
запрос
проходит
по
трем
разным
индексам
. И
по
ним
он
спускается
в
самую
-самую
глубь
поисковой
базы
, разделенную
на
несколько
тысяч
кусков
. Этот
процесс
обозначается,
как
поисковая
кластеризация.
Работа поискового кластера состоит из функционирования более миллиона экземпляров различных программ . Они выполняют всяческого рода задачи , у них разные системные требования и всем им нужно где -то «жить ». Поэтому поисковая кластеризация занимает еще и огроменное количество компьютерного железного хостинга .
Для хранения и передачи всех программ и данных к ним Яндекс использует внутренний торрент -трекер . Число раздач на нем больше, чем на крупнейшем в мире пиратском трекере The Pirate Bay .
Вернемся
к
результатам выдачи
.
В
поисковую выдачу
попадают
наиболее
релевантные
, соответствующие
поисковому
запросу
документы
. Дальше
происходит
ранжирование
- упорядочивание
результатов
поиска
. Проходит
оно
с
помощью
специальной
формулы
. Чтобы
порядок
результатов
каждый
раз
был
качественным
, актуальным и
максимально
релевантным
разработчики Яндекса
придумали
одну
очень
крутую
штуку
.
Метод машинного обучения, с помощью которого строится формула ранжирования Яндекс . Он постоянно модернизирует эту схему: выстраивает комбинации , добавляет и убирает факторы , выставляет коэффициенты . Другая важная характеристика этого метода - возможность индивидуальной настройки формулы ранжирования для узкопрофильных категорий запросов . То естьдля отдельных запросов, например, про кино или компьютерные игры, можно улучшить качество поиска. При этом ранжирование по остальным классам запросов не ухудшится.
Первая формула ранжирования Яндекса составляла примерно 10 байт. На сегодняшний момент - около 100 мегабайт.
Задача поисковика не
просто
находить
иголки
в сеновалах,
но
и
определять
самые
острые
из
них
. И самое удивительное то, как работает Яндекс поиск. Результат выдается за доли секунд.
Десять
первых
наиболее
релевантных
запросов
- как
правило,
это
все, что
нужно
пользователю
. Если
в
этих
запросах
мы
не
находим
то,
что
искали, то
мы
пробуем или
другой
запрос, или меняем поисковик. Но рано или поздно: «Найдется все!»
Скриншоты взяты из лекции Петра Попова.
icon by Arthur Shlain
Здравствуйте, уважаемые читатели блога сайт. Занимаясь или, иначе говоря, поисковой оптимизацией, как на профессиональном уровне (продвигая за деньги коммерческие проекты), так и на любительском уровне (), вы обязательно столкнетесь с тем, что необходимо знать принципы работы в целом для того, чтобы успешно оптимизировать под них свой или чужой сайт.
Врага, как говорится, надо знать в лицо, хотя, конечно же, они (для рунета это Яндекс и ) для нас вовсе не враги, а скорее партнеры, ибо их доля трафика является в большинстве случаев превалирующей и основной. Есть, конечно же, исключения, но они только подтверждают данное правило.
Что такое сниппет и принципы работы поисковиков
Но тут сначала нужно будет разобраться, а что такое сниппет, для чего он нужен и почему его содержимое так важно для оптимизатора? В результатах поиска располагается сразу под ссылкой на найденный документ (текст которой берется уже писал):
В качестве сниппета используются обычно куски текста из этого документа. Идеальный вариант призван предоставить пользователю возможность составить мнение о содержимом страницы, не переходя на нее (но это, если он получился удачным, а это не всегда так).
Сниппет формируется автоматически и какие-именно фрагменты текста будут использоваться в нем решает , и, что важно, для разных запросов у одной и той же вебстраницы будут разные сниппеты.
Но есть вероятность, что именно содержимое тега Description иногда может быть использовано (особенно в Google) в качестве сниппета. Конечно же, это еще будет зависеть и от того , в выдаче которого он показывается.
Но содержимое тега Description может выводиться, например, при совпадении ключевых слов запроса и слов, употребленных вами в дескрипшине или в случае, когда алгоритм сам еще не нашел на вашем сайте фрагменты текста для всех запросов, по которым ваша страница попадает в выдачу Яндекса или Гугла.
Поэтому не ленимся и заполняем содержимое тега Description для каждой статьи. В WordPress это можно сделать, если вы используете описанный (а его использовать я вам настоятельно рекомендую).
Если вы фанат Джумлы, то можете воспользоваться этим материалом - .
Но сниппет нельзя получить из обратного индекса, т.к. там хранится информация только об использованных на странице словах и их положении в тексте. Вот именно для создания сниппетов одного и того же документа в разных поисковых выдачах (по разным запросам) наши любимые Яндекс и Гугл, кроме обратного индекса (нужного непосредственно для ведения поиска — о нем читайте ниже), сохраняют еще и прямой индекс , т.е. копию веб-страницы.
Сохраняя копию документа у себя в базе им потом довольно удобно нарезать из них нужные сниппеты, не обращаясь при этом к оригиналу.
Т.о. получается, что поисковики хранят в своей базе и прямой, и обратный индекс веб-страницы. Кстати, на формирование сниппетов можно косвенно влиять, оптимизируя текст веб-станицы таким образом, чтобы алгоритм выбирал в качестве оного именно тот фрагмент текста, который вы задумали. Но об этом поговорим уже в другой статье рубрики
Как работают поисковые системы в общих чертах
Суть оптимизации заключается в том, чтобы «помочь» алгоритмам поисковиков поднять страницы тех сайтов, которые вы продвигаете, на максимально высокую позицию в выдаче по тем или иным запросам.
Слово «помочь» в предыдущем предложении я взял в кавычки, т.к. своими оптимизаторскими действия мы не совсем помогаем, а зачастую и вовсе мешаем алгоритму сделать полностью релевантную запросу выдачу (о загадочных ).
Но это хлеб оптимизаторов, и пока алгоритмы поиска не станут совершенными, будут существовать возможности за счет внутренней и внешней оптимизации улучшить их позиции в выдаче Яндекса и Google.
Но прежде, чем переходить к изучению методов оптимизации, нужно будет хотя бы поверхностно разобраться в принципах работы поисковиков, чтобы все дальнейшие действия делать осознано и понимая зачем это нужно и как на это отреагируют те, кого мы пытаемся чуток обмануть.
Ясное дело, что понять всю логику их работы от и до у нас не получится, ибо многая информация не подлежит разглашению, но нам, на первых порах, будет достаточно и понимания основополагающих принципов. Итак, приступим.
Как же все-таки работают поисковые системы? Как ни странно, но логика работы у них всех, в принципе, одинаковая и заключается в следующем: собирается информация обо всех вебстраницах в сети, до которых они могут дотянуться, после чего эти данные хитрым образом обрабатываются для того, чтобы по ним удобно было бы вести поиск. Вот, собственно, и все, на этом статью можно считать завершенной, но все же добавим немного конкретики.
Во-первых, уточним, что документом называют то, что мы обычно называем страницей сайта. При этом он должен иметь свой уникальный адрес () и, что примечательно, хеш-ссылки не будут приводить к появлению нового документа (о том, ).
Во-вторых, стоит остановиться на алгоритмах (способах) поиска информации в собранной базе документов.
Алгоритмы прямых и обратных индексов
Очевидно, что метод простого перебора всех страниц, хранящихся в базе данных, не будет являться оптимальным. Этот метод называется алгоритмом прямого поиска и при том, что этот метод позволяет наверняка найти нужную информацию не пропустив ничего важного, он совершенно не подходит для работы с большими объемами данных, ибо поиск будет занимать слишком много времени.
Поэтому для эффективной работы с большими объемами данных был разработан алгоритм обратных (инвертированных) индексов. И, что примечательно, именно он используется всеми крупными поисковыми системами в мире. Поэтому на нем мы остановимся подробнее и рассмотрим принципы его работы.
При использовании алгоритма обратных индексов происходит преобразование документов в текстовые файлы, содержащие список всех имеющихся в них слов.
Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым из них указаны в виде координат те места в вебстранице, где это слово встречается. Кроме позиции в документе для каждого слова приводятся еще и другие параметры, определяющие его значение.
Если вы вспомните, то во многих книгах (в основном технических или научных) на последних страницах приводится список слов, используемых в данной книге, с указанием номеров страниц, где они встречаются. Конечно же, этот список не включает вообще всех слов, используемых в книге, но тем не менее может служить примером построения индекс-файла с помощью инвертированных индексов.
Обращаю ваше внимание, что поисковики ищут информацию не в интернете , а в обратных индексах обработанных ими вебстраниц сети. Хотя и прямые индексы (оригинальный текст) они тоже сохраняют, т.к. он в последствии понадобится для составления сниппетов, но об этом мы уже говорили в начале этой публикации.
Алгоритм обратных индексов используется всеми системами, т.к. он позволяет ускорить процесс, но при этом будут неизбежны потери информации за счет искажений внесенных преобразованием документа в индекс-файл. Для удобства хранения файлы обратных индексов обычно хитрым способом сжимаются.
Математическая модель используемая для ранжирования
Для того, чтобы осуществлять поиск по обратным индексам, используется математическая модель, позволяющая упростить процесс обнаружения нужных вебстраниц (по введенному пользователем запросу) и процесс определения релевантности всех найденных документов этому запросу. Чем больше он соответствует данному запросу (чем он релевантнее), тем выше он должен стоять в поисковой выдаче.
Значит основная задача, выполняемая математической моделью — это поиск страниц в своей базе обратных индексов соответствующих данному запросу и их последующая сортировка в порядке убывания релевантности данному запросу.
Использование простой логической модели, когда документ будет являться найденным, если в нем встречается искомая фраза, нам не подойдет, в силу огромного количества таких вебстраниц, выдаваемых на рассмотрение пользователю.
Поисковая система должна не только предоставить список всех веб-страниц, на которых встречаются слова из запроса. Она должна предоставить этот список в такой форме, когда в самом начале будут находиться наиболее соответствующие запросу пользователя документы (осуществить сортировку по релевантности). Эта задача не тривиальна и по умолчанию не может быть выполнена идеально.
Кстати, неидеальностью любой математической модели и пользуются оптимизаторы, влияя теми или иными способами на ранжирование документов в выдаче (в пользу продвигаемого ими сайта, естественно). Матмодель, используемая всеми поисковиками, относится к классу векторных. В ней используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
В базовой векторной модели вес документа по заданному запросу высчитывается исходя из двух основных параметров: частоты, с которой в нем встречается данное слово (TF — term frequency) и тем, насколько редко это слово встречается во всех других страницах коллекции (IDF — inverse document frequency).
Под коллекцией имеется в виду вся совокупность страниц, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному запросу.
Естественно, что различные поисковики, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса, но суть остается прежней: вес страницы будет тем больше, чем чаще слово из поискового запроса встречается в ней (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах проиндексированных этой системой.
Оценка качества работы формулы асессорами
Таким образом получается, что формирование выдач по тем или иным запросам осуществляется полностью по формуле без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели.
Для этих целей используются специально обученные люди — , которые просматривают выдачу (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы текущей формулы.
Все внесенные ими замечания учитываются людьми, отвечающими за настройку матмодели. В ее формулу вносятся изменения или дополнения, в результате чего качество работы поисковика повышается. Получается, что асессоры выполняют роль такой своеобразной обратной связи между разработчиками алгоритма и его пользователями, которая необходима для улучшения качества.
Основными критериями в оценке качества работы формулы являются:
- Точность выдачи поисковой системы — процент релевантных документов (соответствующих запросу). Чем меньше не относящихся к теме запроса вебстраниц (например, дорвеев) будет присутствовать, тем лучше
- Полнота поисковой выдачи — процентное отношение соответствующих заданному запросу (релевантных) вебстраниц к общему числу релевантных документов, имеющихся во всей коллекции. Т.е. получается так, что во всей базе документов, которые известны поиску вебстраниц соответствующих заданному запросу будет больше, чем показано в поисковой выдаче. В этом случае можно говорить о неполноте выдаче. Возможно, что часть релевантных страниц попала под фильтр и была, например, принята за дорвеи или же еще какой-нибудь шлак.
- Актуальность выдачи — степень соответствия реальной вебстраницы на сайте в интернете тому, что о нем написано в результатах поиска. Например, документ может уже не существовать или быть сильно измененным, но при этом в выдаче по заданному запросу он будет присутствовать, несмотря на его физическое отсутствие по указанному адресу или же на его текущее не соответствие данному запросу. Актуальность выдачи зависит от частоты сканирования поисковыми роботами документов из своей коллекции.
Как Яндекс и Гугл собирают свою коллекцию
Несмотря на кажущуюся простоту индексации веб-страниц тут есть масса нюансов, которые нужно знать, а в последствии и использовать при оптимизации (SEO) своих или же заказных сайтов. Индексация сети (сбор коллекции) осуществляется специально предназначенной для этого программой, называемой поисковым роботом (ботом).
Робот получает первоначальный список адресов, которые он должен будет посетить, скопировать содержимое этих страниц и отдать это содержимое на дальнейшую переработку алгоритму (он преобразует их в обратные индексы).
Робот может ходить не только по заранее данному ему списку, но и переходить по ссылкам с этих страниц и индексировать находящиеся по этим ссылкам документы. Т.о. робот ведет себя точно так же, как и обычный пользователь, переходящий по ссылкам.
Поэтому получается, что с помощью робота можно проиндексировать все то, что доступно обычно пользователю, использующему браузер для серфинга (поисковики индексируют документы прямой видимости, которые может увидеть любой пользователь интернета).
Есть ряд особенностей, связанных с индексацией документов в сети (напомню, что мы уже обсуждали ).
Первой особенностью можно считать то, что кроме обратного индекса, который создается из оригинального документа скачанного из сети, поисковая система сохраняет еще и его копию, иначе говоря, поисковики хранят еще и прямой индекс. Зачем это нужно? Я уже упоминал чуть ранее, что это нужно для составления различных сниппетов в зависимости от введенного запроса.
Сколько страниц одного сайта Яндекс показывает в выдаче и индексирует
Обращаю ваше внимание на такую особенность работы Яндекса, как наличие в выдаче по заданному запросу всего лишь одного документа с каждого сайта. Такого, чтобы в выдаче присутствовали на разных позициях две страницы с одного и того же ресурса, быть не могло до недавнего времени.
Это было одно из основополагающих правил Яндекса. Если даже на одном сайте найдется сотня релевантных заданному запросу страниц, в выдаче будет присутствовать только один (самый релевантный).
Яндекс заинтересован в том, чтобы пользователь получал разнообразную информацию, а не пролистывал несколько страниц поисковой выдачи со страницами одного и того же сайта, который этому пользователю оказался не интересен по тем или иным причинам.
Однако, спешу поправиться, ибо когда дописал эту статью узнал новость, что оказывается Яндекс стал допускать отображение в выдаче второго документа с того же ресурса, в качестве исключения, если эта страница окажется «очень хороша и уместна» (иначе говоря сильно релевантна запросу).
Что примечательно, эти дополнительные результаты с того же самого сайта тоже нумеруются, следовательно, из-за этого из топа выпадут некоторые ресурсы, занимающие более низкие позиции. Вот пример новой выдачи Яндекса:

Поисковики стремятся равномерно индексировать все вебсайты, но зачастую это бывает не просто из-за совершенно разного количества страниц на них (у кого-то десять, а у кого-то десять миллионов). Как быть в этом случае?
Яндекс выходит из этого положения ограничением количества документов, которое он сможет загнать в индекс с одного сайта.
Для проектов с доменным именем второго уровня, например, сайт, максимальное количество страниц, которое может быть проиндексировано зеркалом рунета, находится в диапазоне от ста до ста пятидесяти тысяч (конкретное число зависит от отношения к данному проекту).
Для ресурсов с доменным именем третьего уровня — от десяти до тридцати тысяч страниц (документов).
Если у вас сайт с доменом второго уровня (), а вам нужно будет загнать в индекс, например, миллион вебстраниц, то единственным выходом из этой ситуации будет создание множества поддоменов ().
Поддомены для домена второго уровня могут выглядеть так: JOOMLA.сайт. Количество поддоменов для второго уровня, которое может проиндексировать Яндекс, составляет где-то чуть более 200 (иногда вроде бы и до тысячи), поэтому таким нехитрым способом вы сможете загнать в индекс зеркала рунета несколько миллионов вебстраниц.
Как Яндекс относится к сайтам в не русскоязычных доменных зонах
В связи с тем, что Яндекс до недавнего времени искал только по русскоязычной части интернета, то и индексировал он в основном русскоязычные проекты.
Поэтому, если вы создаете сайт не в доменных зонах, которые он по умолчанию относит к русскоязычным (RU, SU и UA), то ждать быстрой индексации не стоит, т.к. он, скорее всего, его найдет не ранее чем через месяц. Но уже последующая индексация будет происходить с той же частотой, что и в русскоязычных доменных зонах.
Т.е. доменная зона влияет лишь на время, которое пройдет до начала индексации, но не будет влиять в дальнейшем на ее частоту. Кстати, от чего зависит эта частота?
Логика работы поисковых систем по переиндексации страниц сводится примерно к следующему:
- найдя и проиндексировав новую страницу, робот заходит на нее на следующий день
- сравнив содержимое с тем, что было вчера, и не найдя отличий, робот придет на нее еще раз только через три дня
- если и в этот раз на ней ничего не изменится, то он придет уже через неделю и т.д.
Т.о. со временем частота прихода робота на эту страницу сравняется с частотой ее обновления или будет сопоставима с ней. Причем, время повторного захода робота может измеряться для разных сайтов как в минутах, так и в годах.
Такие вот они умные поисковые системы, составляя индивидуальный график посещения для различных страниц различных ресурсов. Можно, правда, принудить поисковики переиндексировать страничку по нашему желанию, даже если на ней ничего не изменилось, но об этом в другой статье.
Продолжим изучать принципы работы поиска в следующей статье, где мы рассмотрим проблемы, с которыми сталкиваются поисковики, рассмотрим нюансы . Ну, и многое другое, конечно же, так или иначе помогающее .
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
 Rel Nofollow и Noindex - как закрыть от индексации Яндексом и Гуглом внешние ссылки на сайте
Rel Nofollow и Noindex - как закрыть от индексации Яндексом и Гуглом внешние ссылки на сайте
 Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
 Траст сайта - что это такое, как его измерить в XTools, что на него влияет и как увеличить авторитетности своего сайта
Траст сайта - что это такое, как его измерить в XTools, что на него влияет и как увеличить авторитетности своего сайта
 СЕО терминология, сокращения и жаргон
СЕО терминология, сокращения и жаргон
 Релевантность и ранжирование - что это такое и какие факторы влияют на положение сайтов в выдаче Яндекса и Гугла
Релевантность и ранжирование - что это такое и какие факторы влияют на положение сайтов в выдаче Яндекса и Гугла
 Какие факторы поисковой оптимизации влияют на продвижение сайта и в какой степени
Какие факторы поисковой оптимизации влияют на продвижение сайта и в какой степени
 Поисковая оптимизация текстов - оптимальная частота употребления ключевых слов и его идеальная длина
Поисковая оптимизация текстов - оптимальная частота употребления ключевых слов и его идеальная длина
 Контент для сайта - как наполнение уникальным и полезным контентом помогает в современном продвижении сайтов
Контент для сайта - как наполнение уникальным и полезным контентом помогает в современном продвижении сайтов
 Мета теги title, description и keywords мешают продвижению
Мета теги title, description и keywords мешают продвижению
 Апдейты Яндекса - какие бывают, как отслеживать ап Тиц, изменения поисковой выдачи и все другие обновления
Апдейты Яндекса - какие бывают, как отслеживать ап Тиц, изменения поисковой выдачи и все другие обновления